
HTTP is a stateless protocol meaning that each request does not save any information. When you login into a web application, it must somehow maintain that you are logged in. One of the common approaches to that problem is using a session identifier.
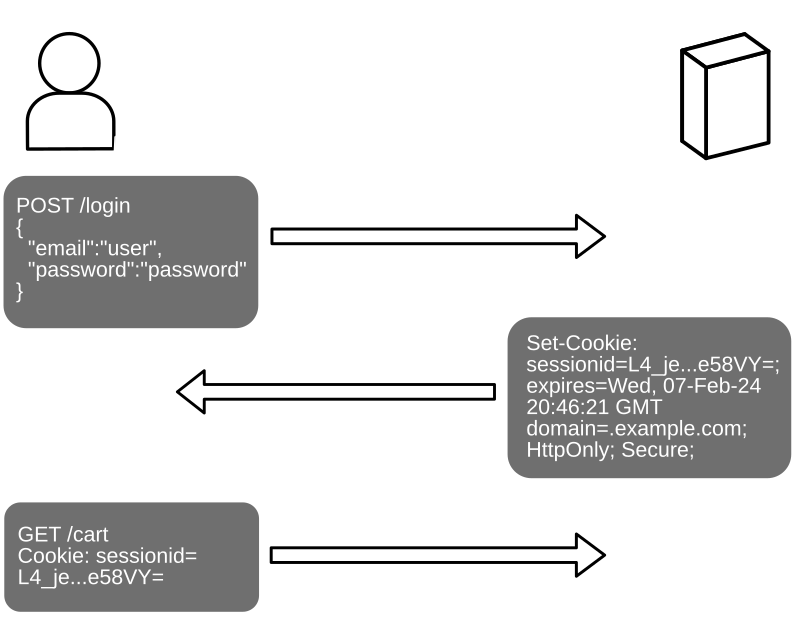
- Upon login, the user submits their credentials over an HTTPS connection
- The server tells the browser to set a cookie for the session ID.
The session ID has the equivalent significance as their credentials. With the session, the user is able to remain “logged in.” - Each following request includes the session ID until the session expires or the user logs out.
Important Qualities
“HttpOnly” Session Cookie
An HttpOnly cookie prevents JavaScript from accessing it. This is important to avoid attacks where malicious JavaScript attempts to access the cookie and send it back to the attacker.
“Secure” Session Cookie
Some websites allow HTTP and HTTPS traffic. A “Secure” cookie requires that it only be sent over a secure HTTPS connection (preventing the cookie from being sniffed or leaked over insecure connections).
Hard to Guess
Because a session ID allows anyone with it to be “logged in” as that user, it is imperative to make it difficult to guess. Several qualities contribute to this:
- Generated with a cryptographic algorithm
- Other methods may allow the attacker to guess based on time or other factors
- Long
- Trivial since it is stored
Unique
Session IDs must be unique (not just random). It would be unfortunate if the same session ID was assigned to two users. The application may mistakenly treat one user as the other.
Conclusion
Sessions play a big role in authentication and account management in many web apps.
I hope that you better understand at a high-level what sessions are and how they are handled in web applications.